Calico 学习及源码分析
背景
如何选取合适的网络插件:
1.集群环境因素
如果集群节点机器为虚拟机,不允许机器之间直接二层互联(所谓二层互联也就是说通过交换机可以直接通信,而可以通过交换机直接通信则说明通过交换机互联的机器处于同一个子网中,不同子网直接通信则需要用到路由器), 必须要带有IP地址这种三层的内容才能去做转发,或者限制机器只能使用某些IP等约束,这种情况只能使用overlay模式去实现。常见的有Flannel-vxlan,Calico-ipip,Weave等。
物理机环境同一个子网底层网络可以通过交换机直接通信,此时我们可以使用underlay模式或者路由模式的网络插件。这样避免了使用vxlan封包解包d导致性能降低,常见的插件有Flannel-hostgw,Calico-bgp等。
2.性能因素
pod 创建速度,在pod需要扩容时,overlay模式创建pod速度快,内核接口就可以完成这些操作。underlay模式需要准备底层网络资源,速度较慢。
其次,overlay模式包含封包解包,会带来一些包头的损失、CPU 的消耗等,对网络性能的要求比较高,比如说机器学习、大数据这些场景就不适合使用 Overlay 模式。
calico

calico网络模型主要的组件
- Felix:
每一个节点上的agent进程,监听etcd,当有新节点加入或者新的容器创建,felix为它设置网卡,IP,MAC,然后更新节点路由表,添加策略到Iptables
-
etcd: 数据存储
-
BGP Client
每一个节点上都有BGP Client,监听felix写入的路由信息,然后通过BGP协议广播到其他Host节点上去,实现网络互通。该模式比较适合集群规模较小的场景,因为每一个BGP Client需要和集群其他节点互连。集群规模较大时,路由表会被撑满。
- BGP Route Reflector:
针对BGP Client存在的问题,对于大规模集群,可以采用BGP的Router Reflector的方法,使所有BGP Client仅与特定Router Reflector节点互联并做路由同步,从而大大减少连接数。

calico 网络模式
calico 作为容器网络方案最大的特点就是它提供了纯三层网络报文转发方案,也就是说每个节点中的容器都可以通过IP地址来直接通信,中间可以通过路由转发找到对方。对比于flannel-hostgw方案,虽然也是通过路由实现通信,但是它依赖于集群所有节点二层连通,然后通过更新每个节点路由的方式实现通信,也就是说flannel-hostgw 方案需要所有节点在同一个子网中,不在同一个子网无法通信。
calico可以实现跨子网通信,是因为他在每一个集群节点中加入了虚拟路由(vrouter),通过BGP路由协议,使得每一个节点中的路由信息可以被传播到其他路由设备,实现三层网络通信。 �������������������������������������������� ���������������������������������������� ��������������������������������������� ��������������������������������������� ��������������������������������� 但是,并不是所有的网络都支持BGP路由协议,calico也提供了overlay模式解决方案—ipip模式
IPIP模式
和其他overlay模式实现的原理一样,ipip模式是在各个节点之间架起一个隧道,使用节点IP封装原始IP报文,启用ipip模式是,calico会在每一个节点上创建一个名字为tunl0的虚拟网络接口。
ping数据包流向图
我们来分析一下一个集群中处于两个不同node的pod数据包是如何传输的,集群网络模式是calico-ipip
node2节点ip为172.31.127.252,node2中pod2的ip为10.100.9.206
node1节点ip为172.31.112.2,node1中pod1的ip为10.100.15.150,如下图所示:

- pod网络分析
首先进入pod1
$ kubectl exec -it pod1 /bin/bash
查看pod1中包含的网络设备,可以看到pod1中只包含lo和eth0
$ ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
4: eth0@if26: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1440 qdisc noqueue state UP group default
link/ether ce:83:2b:89:af:9e brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.100.15.150/32 scope global eth0
valid_lft forever preferred_lft forever
- node网络
查看node1中包含的网络设备
$ ip addr
...省略部分
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:16:3e:02:03:5c brd ff:ff:ff:ff:ff:ff
inet 172.31.112.2/20 brd 172.31.127.255 scope global dynamic eth0
valid_lft 311927346sec preferred_lft 311927346sec
4: tunl0@NONE: <NOARP,UP,LOWER_UP> mtu 1440 qdisc noqueue state UNKNOWN group default qlen 1000
link/ipip 0.0.0.0 brd 0.0.0.0
inet 10.100.15.128/32 brd 10.100.15.128 scope global tunl0
valid_lft forever preferred_lft forever
26: cali3ef8aad4b4e@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1440 qdisc noqueue state UP group default
link/ether ee:ee:ee:ee:ee:ee brd ff:ff:ff:ff:ff:ff link-netnsid 1
我们可以看到node1中包含的主要设备有eth0,tunl0和cali3ef8aad4b4e。eth0是node1网卡,tunl0就是calico隧道名称,那cali3ef8aad4b4e又是什么呢?我们回到pod1中 运行命令:
$ kubectl exec -it pod1 /bin/bash
$ ip link show eth0
4: eth0@if26: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1440 qdisc noqueue state UP mode DEFAULT group default
link/ether ce:83:2b:89:af:9e brd ff:ff:ff:ff:ff:ff link-netnsid 0
可以看到eth0@if26这个关键字,eth0连接的设备的index为26。其实这个设备就是veth pair,K8s在创建Pod的时候,会创建一个veth pair设备。设备的一端是pod2的网卡eth0,另一端就是我们在node中看见的cali3ef8aad4b4e了
此时我们可以将整个node和pod的网络设配体现在一张图上:
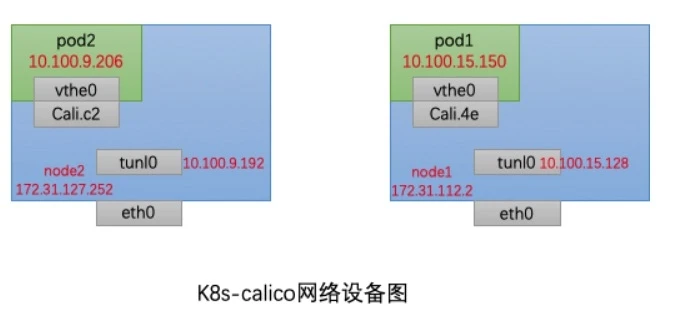
现在我们来分析一下数据包从pod2到pod1流动的过程:

我们知道,pod2中的网卡veth0和Cali.c2是一对veth pair,这个veth pair相当于一根网线,他们之间数据直接互通的。此时数据包内的源地址和目标地址为
10.100.9.206-->10.100.15.150
数据包通过veth pair从pod到达node2节点,我们来查看node2节点的路由表,我们发现下面这一条
$ route -n
Destination Gateway Genmask Flags Metric Ref Use Iface
10.100.15.0 172.31.112.2 255.255.255.0 UG 0 0 0 tunl0
发往目的地10.100.15.xx的ip都需要经过tunl0设备,发往172.31.112.2网关。经过tunl0报文会再封一层ip头。此时数据包源地址和目标地址为
172.31.127.252(node2的ip地址)-->172.31.112.2(node1网关,此时也是node1的ip地址):10.100.9.206-->10.100.15.150
然后我们在node2的路由表中继续发现另外一条路由信息:
Destination Gateway Genmask Flags Metric Ref Use Iface
172.31.112.0 0.0.0.0 255.255.240.0 U 0 0 0 eth0
发往172.31.112.xx的数据包需要通过eth0网卡,此时数据包被发送到了node2的eth0,然后数据包发往node1节点(172.31.112.2)的eth0,到达了node1节点。
到达node1节点后,数据包经由eth0到达tunl0然后数据解包,发现目标地址为10.100.15.150,经过路由匹配数据包发送给Cali.4e,经过veth pair到达pod1内部,完成通信。
- 同一个Node之间pod通信
同一个node之间的pod通信需要经过tunlo设备吗,我们可以通过路由表来进行分析
如下图所示,我们在pod2中ping pod3的ip地址10.100.9.207,这两个pod在同一个node节点上,我们进入该节点查看路由表
我们发现发往10.100.9.207的数据包都会发往cali7116f2b12fa这个设备上,而cali7116f2b12fa这个设备就是node节点上pod3 veth pair对的一端。
Destination Gateway Genmask Flags Metric Ref Use Iface
10.100.9.207 0.0.0.0 255.255.255.255 UH 0 0 0 cali7116f2b12fa
也就是说,pod2发往pod3的数据包,不会经过tunlo设备,而是直接发往pod3所在veth pair对calico那一端。
